
文章目录
移动互联网时代,OIDC变得越来越流行,如果你在使用Android,AWS,Microsoft Azure,Salesforce或Google,那么你很可能已经在使用OIDC协议和JWT令牌。本文是深入理解JSON Web Token系列第一部分,追本溯源,JWT是移动互联网时代手机app在身份验证 (Authentication)和授权 (Authorization) 中使用最广泛的令牌规范,而在JWT被发明前,SAML Assertion令牌曾一度风靡Web浏览器主导的时代。为了解JWT的历史,本文以身份验证中,如何避免对用户重复进行验证为线索,依次介绍了服务端Session,服务端Session的改进方法,SAML协议以及现在使用最广泛的的OIDC协议。其中OIDC协议使用了本文的主角JWT。
什么是身份验证
在日常生活中,有许多需要身份验证的场景。比如进入公司的大楼时,需要携带工牌;打卡上班时,需要指纹识别;打开工作电脑时,需要输入密码。
身份验证(Authentication)的目的是确认当前所声称为某种身份的用户,确实是所声称的用户。在计算机、通信等领域,我们一般有三种方法来确认用户的身份(Authenticate),基于用户知道的东西,基于用户拥有的东西,以及基于用户的生物特征的方法
- 基于用户知道的东西:比如密码,安全问题等
- 基于用户拥有的东西:比如身份证,安全令牌(手机软件令牌或者物理令牌),体内植入装置等
- 基于用户的生物特征:比如指纹,视网膜,声纹,面部信息,签名等
Web服务一般通过前两种方式来验证用户的身份。最常见的就是通过用户名和密码来确认用户的身份,确认过身份的用户称为为授权用户(Authenticated user)。
比如下图所示的例子,Web服务器通过HTTP协议向授权用户提供对于资源A的访问。Web服务器是向用户提供Web服务的机器。在这里,你可以想象下图中的Web服务器是一个视频网站的后端,资源A可以是注册用户才能观看的视频,客户端可以是手机app或者是浏览器。
在这里,用户通过客户端向Web服务器提供用户名和密码,Web服务器则在身份验证数据库中检查用户的真实性(authenticity)。这里对Web服务器的逻辑有很多省略,比如,用户注册后,身份验证数据库就保存了用户的用户名和密码,所以,验证用户名和密码就是在身份验证数据库中找到该用户,并且检查用户提供的密码是否与数据库中的密码匹配。
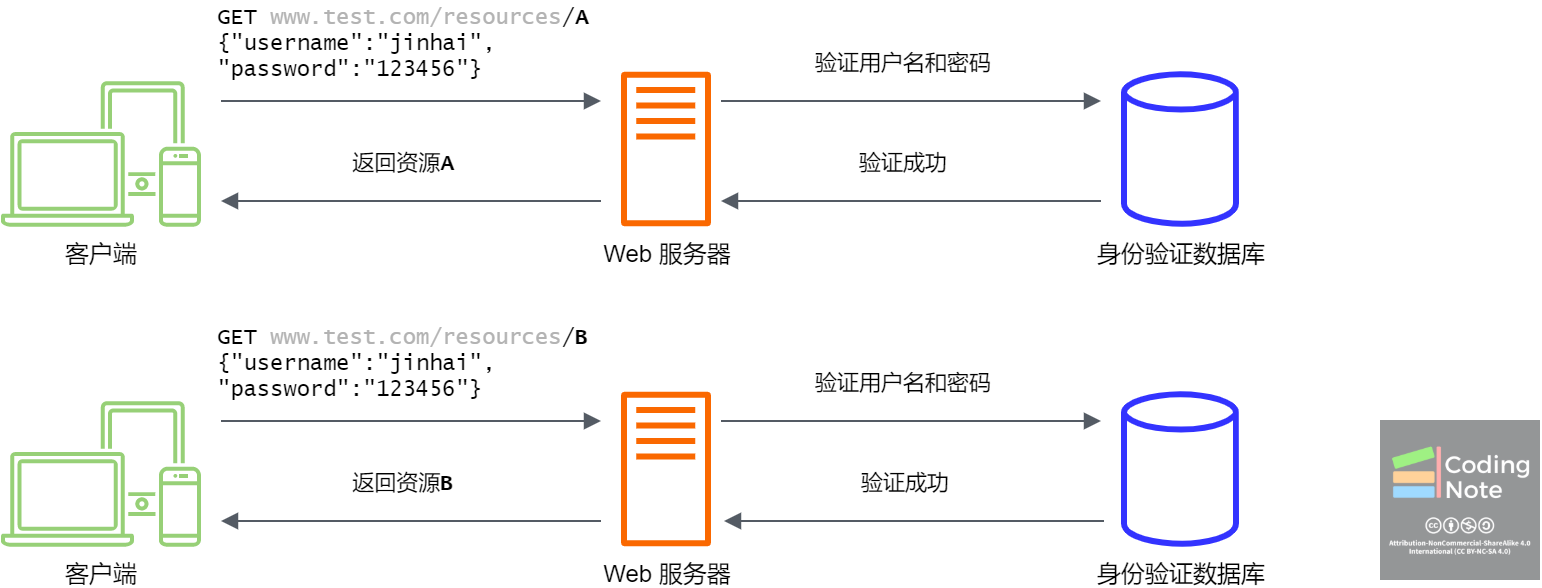
如果同一个用户想要访问资源B,那么就如同访问资源A一样。用户需要通过客户端再次向Web服务器提供用户名和密码。你可能也发现了,这里的用户体验是很不好的,因为用户每访问一个资源,就需要再次输入用户名和密码。没有一个现代Web服务会要求用户这么做。
如何避免重复身份验证?
服务端Sessions
早期的Web服务器会通过保存用户Sessions (会话信息) [1]的方式避免用户重复输入用户名密码。在用户第一次向Web服务器请求资源时,Web服务器在身份验证数据库中检查用户的真实性,如果用户身份验证成功,Web服务器则生成一个键值对(Key-Value Pair)保存在Web服务器的内存中。其中键为Session ID(会话ID),值为与身份验证有关的信息,比如用户名,身份有效期等。接下来,Web服务器把资源A和Session ID一并返回给客户端,客户端会替用户保存Session ID。
当用户想要访问资源B时,客户端会把Session ID直接发送给Web服务器,不需要用户再次输入用户名和密码。Web服务器收到请求后,在它的内存中验证与Session ID对应的Session,如果验证成功,则返回资源B。为了安全起见,Session ID一般都存在有效期,在有效期内,用户访问Web服务器上的资源都不需要再次输入用户名和密。
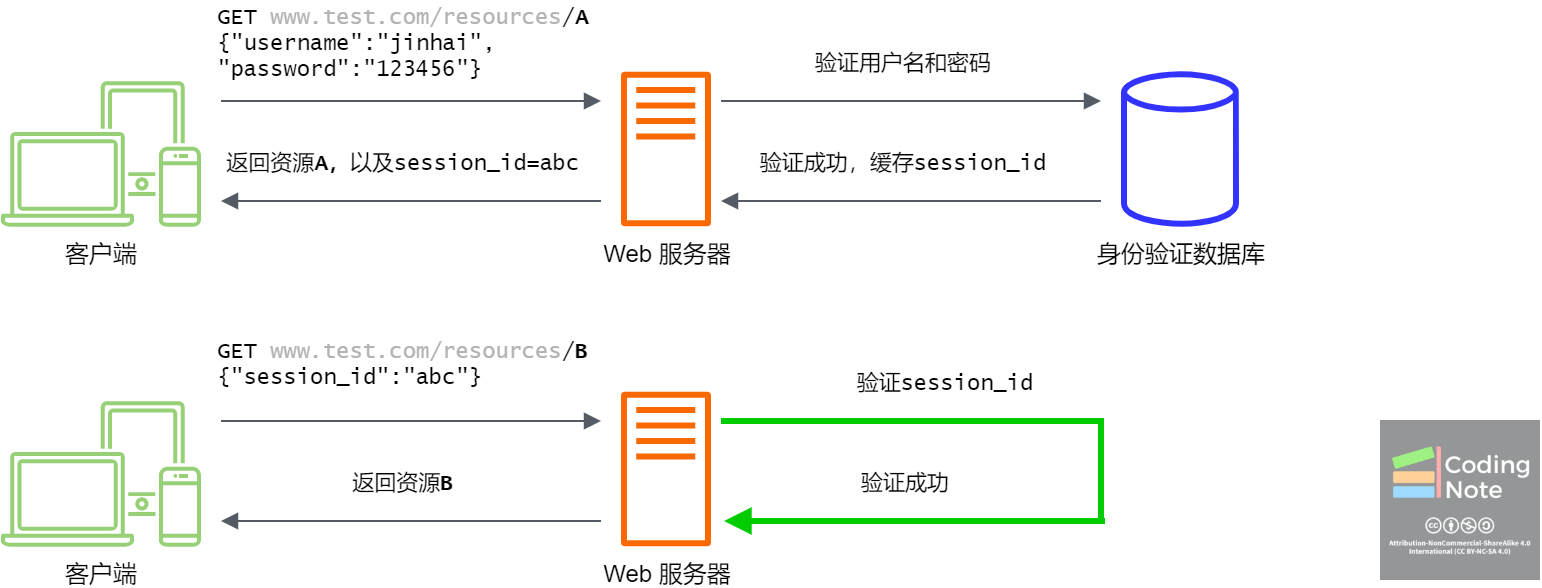
服务端Sessions的缺陷
服务端Sessions曾一度是避免重复身份验证的方法,直到使用Web服务的用户越来越多,多到一个Web服务器已经无法满足用户请求了。为了满足日益增长的用户请求,一个常见的作法是对Web服务的架构进行水平拓展 (Horizontal Scaling) [2]。然而在水平拓展后,服务端Sessions避免重复身份验证的方法就失效了。
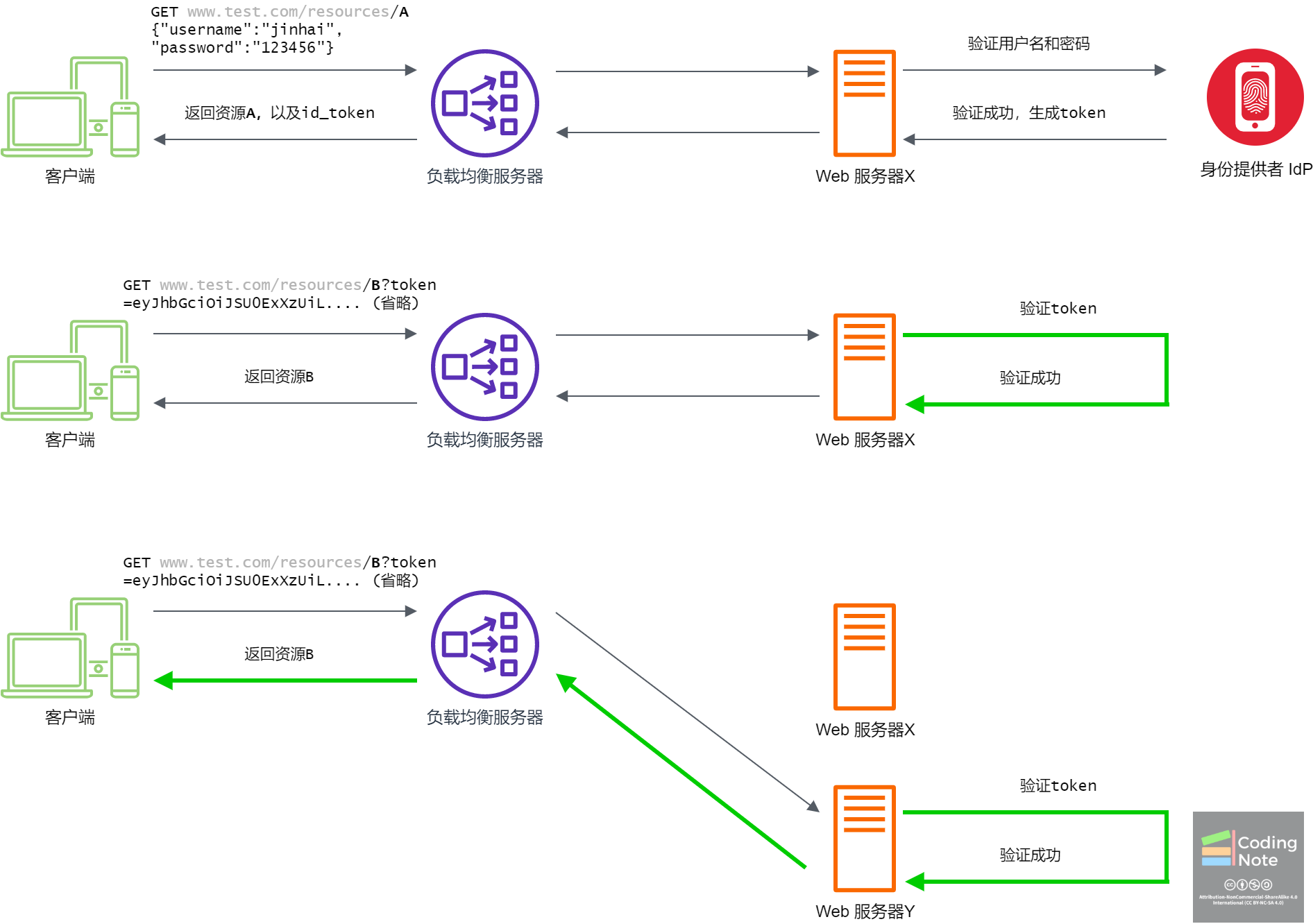
Web服务的架构进行水平拓展后,客户端不再直接与Web服务器进行交流。取而代之是负载均衡服务器 (Load Balancer) [3],负载均衡服务器就像是包工头,它把来自客户端的请求路由给不同的Web服务器。如下图所示,客户端通过负载均衡服务器访问Web服务器X上的资源,服务器X保存了用户的Session。当客户再次访问服务器X上的资源时,服由于服务器X保存了用户的Session,用户的身份验证成功。如果客户端访问了服务器Y,由于服务器Y没有保存用户的Session,用户的身份验证失败。所以服务端Sessions的方法在服务器水平拓展的情况下是有缺陷的。
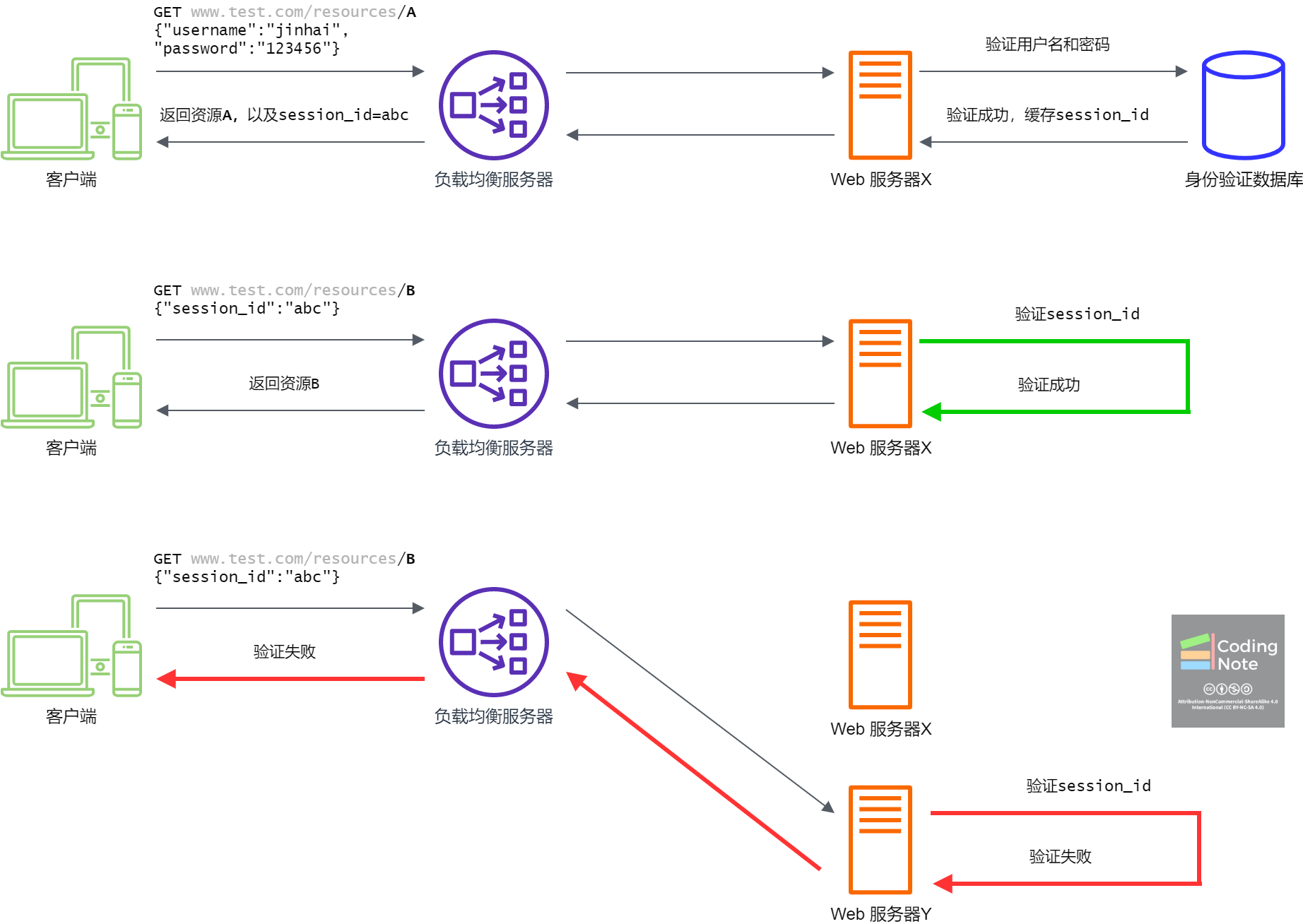
服务端Sessions方法的改进
服务端Sessions方法在水平拓展的架构下是有缺陷的,有没有什么办法可以改进该方法,使其在水平拓展的架构下能够继续适用呢?方法是有的,下面便依次介绍三种方法,需要注意的是,下面三种方法也有各自的缺陷。
- 粘性会话 (load balancer sticky session)
- 内存同步 (memory replication)
- 内存数据库 (in-memory database)
服务端Sessions的改进:粘性会话
负载均衡服务器一般不会保证同一用户的请求会被路由到同一个服务器,这是造成服务端Sessions方法失效的直接原因。如果对负载均衡服务器加以改造,让同一用户的请求路由到同一个服务器,那么服务端Sessions方法就可以继续使用下去了。一般负载均衡服务器可以通过客户端Cookie,或者客户端IP来标识和追踪每位用户,为不同用户分配标识ID。根据标识ID,负载均衡服务器可以把某用户的所有请求路由到特定服务器上。这种方法叫做粘性会话 (Sticky Session),形象地说就是会话粘到了特定的服务器上。
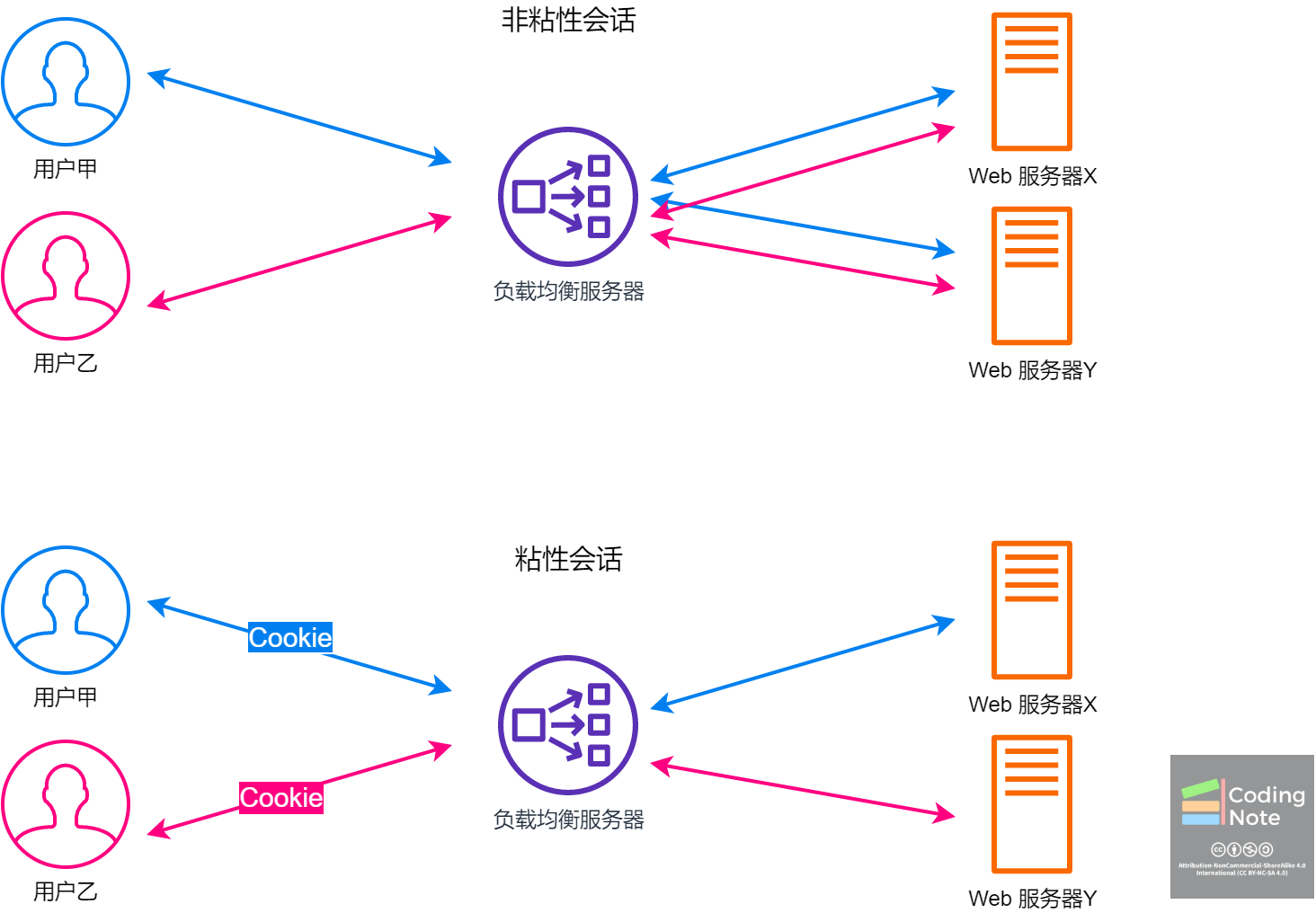
负载均衡服务器的主要目的是均衡不同服务器上的负载,所以当新的请求到来时,一般要把新请求路由到负载最轻的服务器上,以便让不同的服务器有差不多负载。而采用了粘性会话的负载均衡服务器,由于要保证来自相同的用户的请求被路由到特定的服务器,会导致不同服务器上的负载不均衡。造成有些Web服务器负载过重,而有些Web服务器负载过轻的问题。

服务端Sessions的改进:内存同步
之前的方法需要把特定的用户的Session保存在特定的服务器上,这样用户需要访问特定服务器才能取得之前的Session。有没有什么方法能放宽这种限制,让用户不需要访问特定的服务器呢?
一种按照这种思路解决问题的方法是内存同步 (Memory Replication),当Web服务器X生成用户Session时,不仅在自己的内存中保存一份,同时也向服务器Y发送请求,让服务器Y也保存一份用户的Session。这样不论用户访问哪个服务器,都可以通过Session ID取得相应的Session。
然而在不同的服务器上进行内存同步不是一件简单的事情,这里会涉及到分布式系统中的许多问题。比如,用户在服务器Y还没来的及保存Session时就访问了服务器Y,那么服务器Y会要求用户输入用户名和密码,生成该用户的Session并请求服务器X也保存该信息,那么服务器X上的Session还没来及使用就已经作废了。
服务端Sessions的改进:内存数据库
不在特定Web服务器上保存Session,这样用户就不需要访问特定的Web服务器来获取上面存放的Session了。另外一种按照这种思路解决问题的方法是使用数据库,这时Web服务器不在自己的内存中保存Session,而是在一个所有服务器都可以存取的数据库中保存Session。通常,为了减少时延,会采用下图所示的内存数据库 (In-memory database)。因为,内存数据库的数据完全存放在内存中,相比传统数据库有更高的存取速度。
如下图所示,不论用户的请求是被负载均衡服务器路由到了哪个Web服务器,用户的Session都可以在内存数据库中根据Session ID找到。
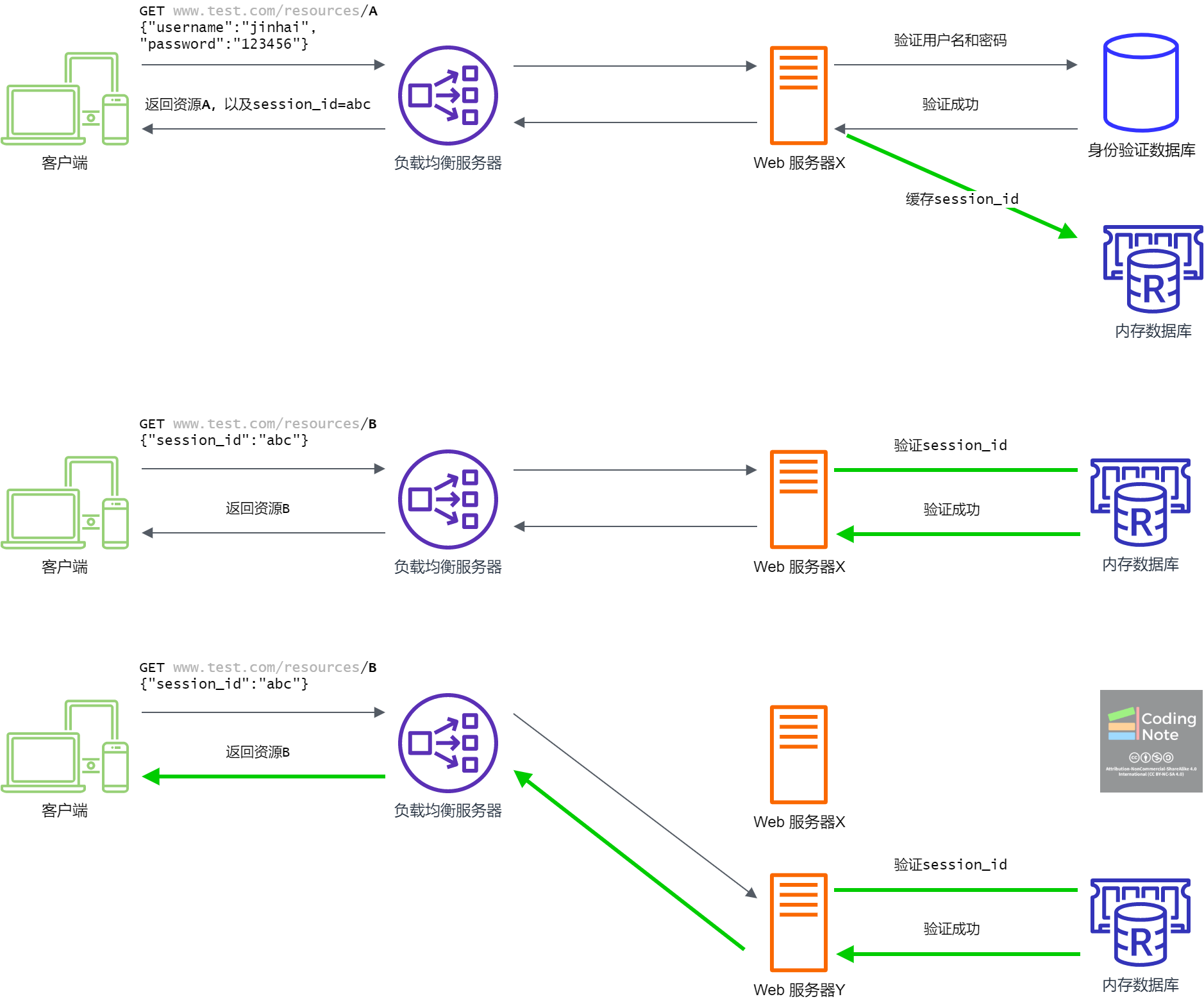
内存数据库虽然可以解决内存同步的问题,但是额外的数据库会带来架构复杂性的提升:内存数据库一旦失效,整个系统的会话就没法运作,这是典型的单点故障 (Single ponit of failure) [4],会严重影响Web服务的可用性 (Availability) [5]。为了去除单点故障,我们可以把内存数据库放到另外一个负载均衡服务器后面,并增加一个内存数据库的热备份,但是,这样的架构太复杂了。此外,额外的数据库会带来额外的时间开销。即便内存数据库的存取速度很快,但是因为有额外的网络时延,内存数据库还是要慢上许多。
基于令牌的身份验证 SAML协议
服务端Session的弊端让人们思考避免重复身份验证的其他方法。大约在2001年,为了解决网页浏览器SSO (单点登录) [6] 的需求,SAML (安全主张标记语言) [7] 被发明出来。SSO是一个比较常见的需求,比如手机登陆微信账号后,访问CSDN,图灵教育,InfoQ等网站时可以选择微信免密码登陆,这就是一种SSO。
SAML规范定义了三个角色:委托人(通常为一名用户)、身份提供者(IdP),服务提供者(SP)。
如下图,在用SAML解决的使用案例中,身份验证流程如下
- 用户从服务提供者那里请求一项服务,比如登陆CSDN网站。
- CSDN网站返回一个SAMLrequest。
- 浏览器收到SAMLrequest,把用户跳转到IdP的身份验证网页,比如微信登陆页面。这时用户可以输入用户名和密码登陆,或者扫码登陆。
- IdP验证用户身份后返回SAML response (其中包括SAML Assertion)。
- 浏览器收到SAML response (其中包括SAML Assertion)后,把SAMLresponse发送给SP,SP检查SAMLresponse,验证成功后,用户便可以获得SP的服务,比如登陆CSDN网站。
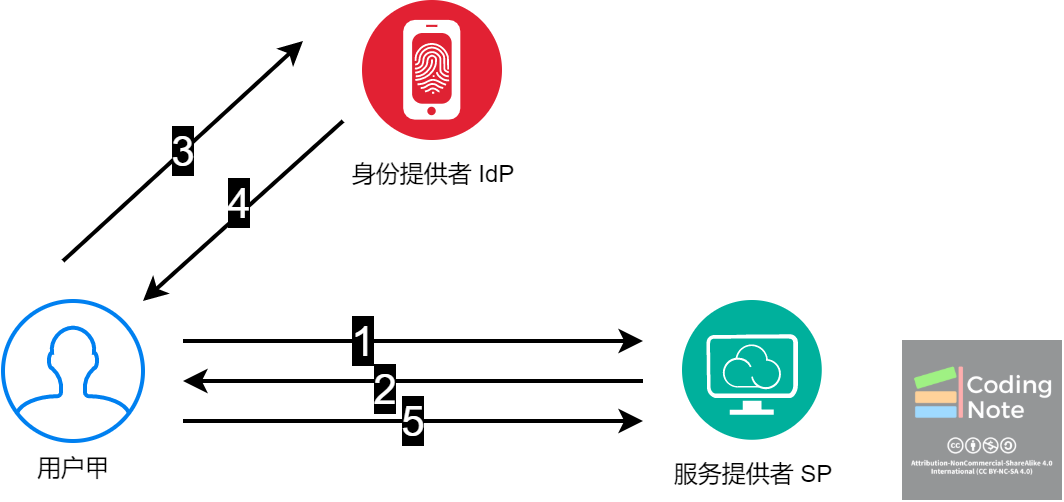
SAML是一种**基于令牌的身份验证 (Token based Authentication)和授权 (Token based Authorization)**的协议。其协议背后的一般概念可以总结如下。 用户向IdP输入他们的用户名和密码,以获得一个令牌,该令牌允许他们获取特定资源时无需使用用户名和密码。 一旦获得了令牌,用户就可以向SP提供令牌并在一段时间内可以访问特定资源。
基于令牌的身份验证是怎么解决用户重复登陆问题的?
虽然SAML是为了解决SSO需求而发明的,但是它连带着解决了用户身份重复验证的问题。作为对比,服务端Session方法需要在服务端保存用户的身份信息,也就是说,服务器需要保存用户的状态。在有多个服务器的情况下,服务器之间需要同步用户的状态,实现起来不简单而且易出错;而基于令牌的方法不需要在服务端保存用户的身份信息,也就是说,服务器只需要验证令牌的有效性就可以了。验证令牌涉及到对称以及非对称加密算法,在单个或者多个服务器的情况下,验证令牌的算法没有区别。
SAML的继任者OIDC
SAML被发明的时代Web浏览器占据主导地位,SOAP [8]和XML分别是Web协议和Web数据交换格式的代表。所以SAML协议与SOAP和XML有着紧密地联系。SAML通过SOAP在用户,IdP和SP间使用XML传输信息,并且SAML定义的令牌,SAML Assertion,就使用了XML格式。
SAML的缺陷
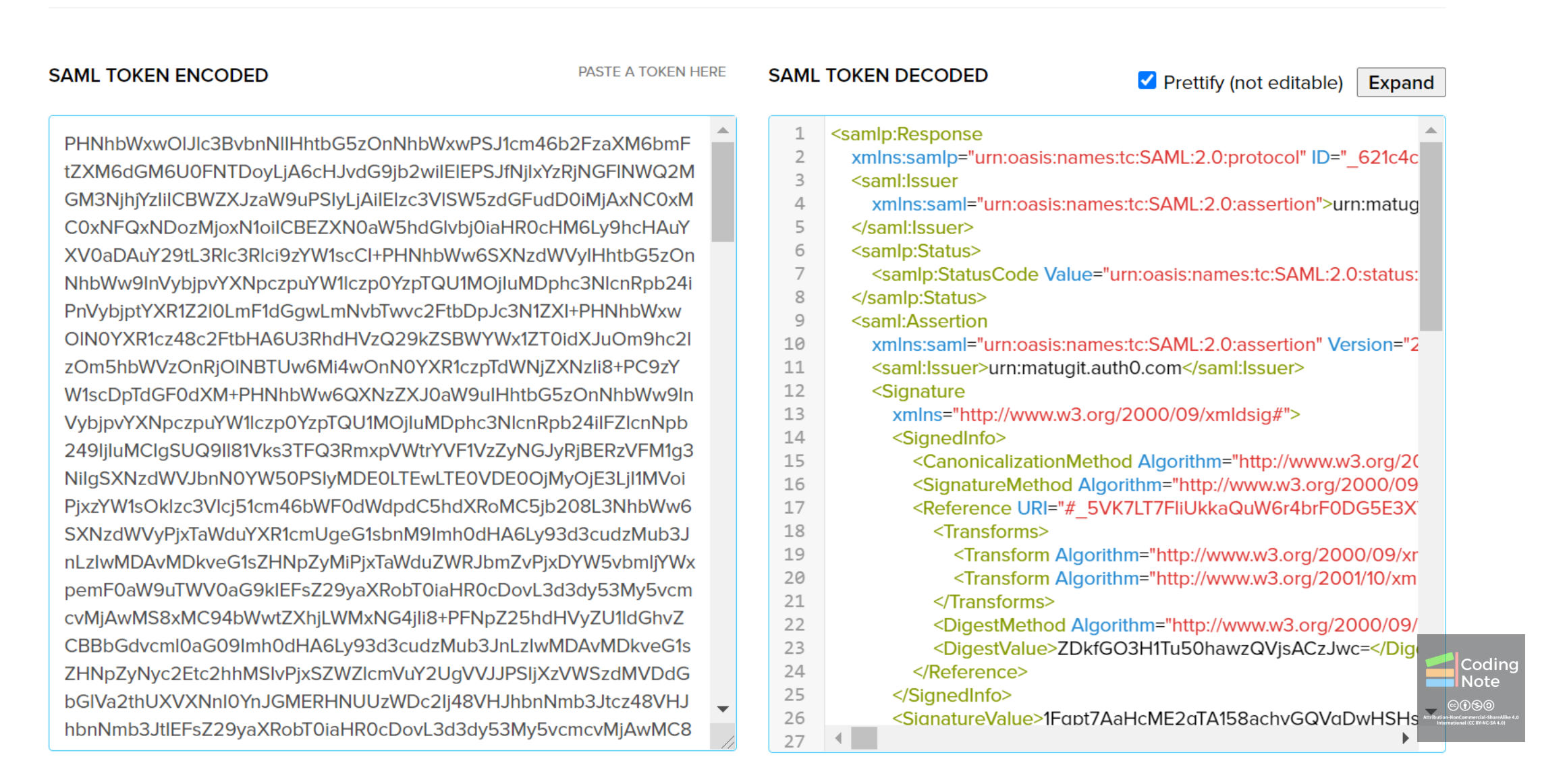
屏幕截图中的网站是 https://samltool.io/,展示了SAML定义的令牌 SAML Assertion
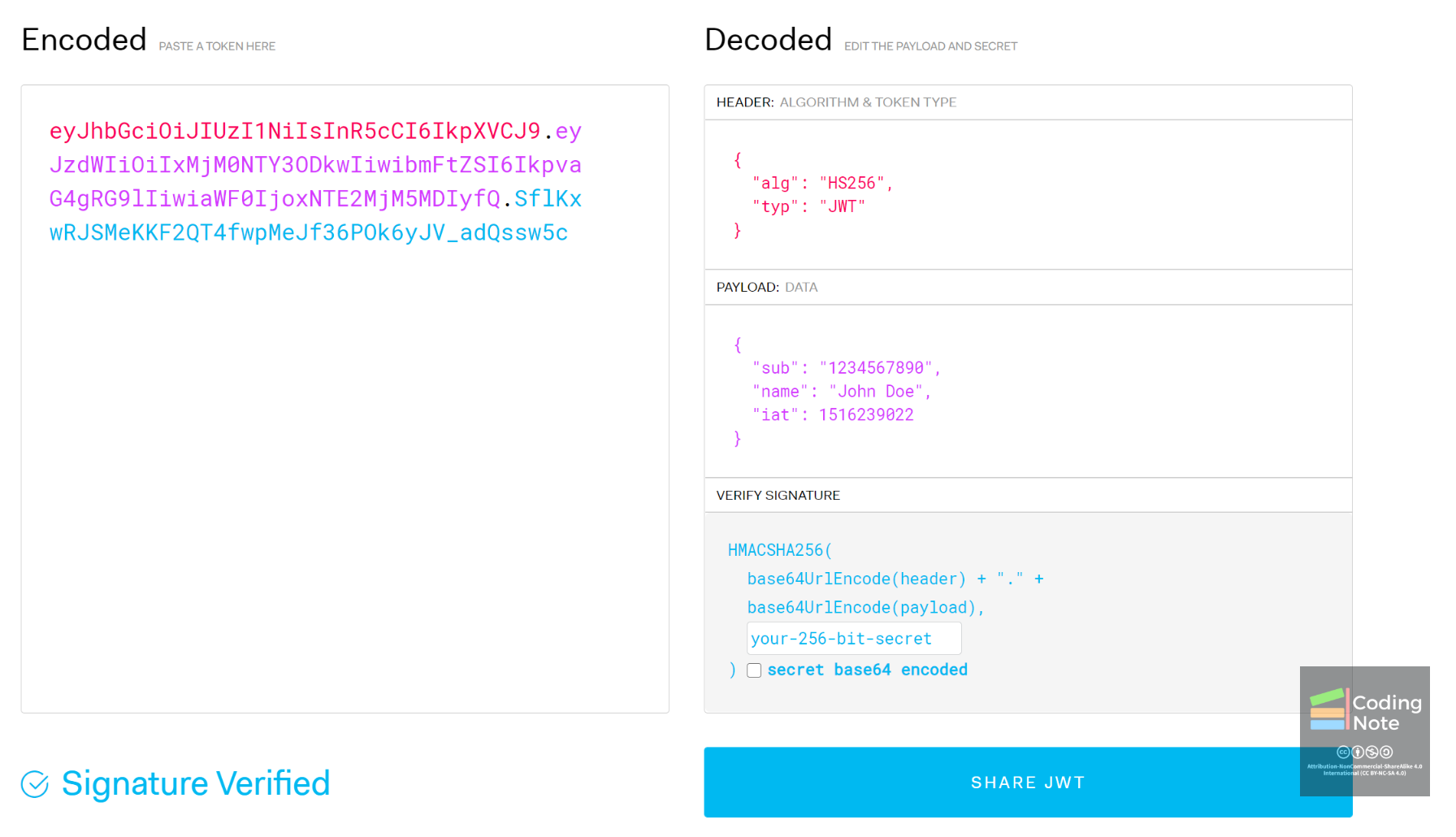
屏幕截图中的网站是 https://jwt.io/,展示了具有JSON格式的令牌JWT
然而随着移动互联网时代到来,SOAP和XML分别被REST [9]和JSON代替,这时与SOAP和XML紧密联系的SAML协议的弊端也逐渐显现。其中最重要是基于XML格式的令牌体积巨大,定义复杂,不易在移动互联网中传输和使用。因为这些缺点,SAML定义的令牌,SAML Assertion近年来又被JSON的令牌 JWT (JSON Web Token) RFC-7519 所代替的趋势。
为什么XML格式的令牌不易传输
XML格式的令牌不易传输是相较于JSON格式的令牌而言的。首先XML格式冗长,不仅包含数据,而且包含数据定义,虽然具有自解释性,但是相比于只包含数据的JSON格式,XML格式保存令牌的体积比JSON大。
为什么XML格式的令牌不易使用
XML格式的令牌不易使用是相较于JSON格式的令牌而言的。JSON是JavaScript编程语言的一等公民,JavaScript可以直接操作JSON格式的数据。所以JavaScript应用之间几乎都是用JSON进行数据交换,比如REST,JSON-和GraphQL。虽然JavaScript也可以使用XML,但是相比JSON,使用XML的过程更复杂,比如需要解析和序列化的工具。
因为SAML Assertion的缺陷,不仅是SAML Assertion,SAML本身也岌岌可危。诞生于2014年的OIDC (Open ID Connnect) 协议在设计时主要考虑了移动互联网和手机app的需求。所以OIDC设计的主要原则是易于传输和使用。OIDC的用户授权 (Auhorization) 基于OAuth2,并在OAuth2的基础上提供了用户验证 (Authentication) ,成为集用户验证和用户授权于一体的协议,就和SAML一样。于SAML不同的是,OIDC在令牌上,不仅支持 SAML Assertion,更是支持具有JSON格式的JWT。有了JWT加持,OIDC协议比SAML更易于传输和使用。
由于OIDC协议支持REST和JSON之类的现代技术,移动互联网时代的Web应用以及手机app可以更方便的实现OIDC协议。OIDC协议非常适合与SPA (Single-Page Application) 和手机app和一起使用,而在这些应用程序中,使用SAML会很困难。所以在移动互联网时代,OIDC变得越来越流行,如果你在使用Android,AWS,Microsoft Azure,Salesforce或Google,那么你很可能已经在使用OIDC协议和JWT令牌 [10]。
SAML为解决了企业SSO的需求而诞生,虽然仍然被广泛地应用于企业身份验证中 [11],但是由于其协议过于学术化(复杂),而且支持它library太少了。所以现在也有被OICD协议的替代的趋势。
因为JWT的体积很小,可以在HTTP协议中作为URL的一部分被传输,如下图所示
拓展阅读
身份验证 (Authentication)的三种方法
身份验证的目的是确认用户的真实性 (Authenticity),验证用户 (Authenticate) 的方法可以大致归为以下三种,基于用户知道的东西,基于用户拥有的东西,基于用户的生物特征
- 基于用户知道的东西:比如密码,安全问题
- 基于用户拥有的东西:比如身份证,安全令牌(手机软件令牌或者物理令牌),体内植入装置
- 基于用户的生物特征:比如指纹,视网膜,声纹,面部信息,签名
服务端Session,客户端Session的比较
https://stackoverflow.com/questions/6922145/what-is-the-difference-between-server-side-cookie-and-client-side-cookie
客户端Seesion https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Cookies
SAML协议,OAuth2协议和OICD协议的比较
以下内容节选自 https://security.stackexchange.com/questions/82587/what-are-the-differences-between-json-web-tokens-saml-and-oauth-2
1 | +----------+----------------+-------------------------------+ |
JWT和XAML Assertion的比较
以下内容节选自 https://tools.ietf.org/html/rfc7519#appendix-B
1 | Appendix B. Relationship of JWTs to SAML Assertions |
JWT和SWT的比较
以下内容节选自 https://tools.ietf.org/html/rfc7519#appendix-C
1 | Appendix C. Relationship of JWTs to Simple Web Tokens (SWTs) |
参考
- https://en.wikipedia.org/wiki/Authentication
- https://auth0.com/blog/how-saml-authentication-works/
- https://www.w3.org/2001/sw/Europe/events/foaf-galway/papers/fp/token_based_authentication/
- https://auth0.com/docs/tokens/access-tokens
- https://www.informationweek.com/software/information-management/saml-the-secret-to-centralized-identity-management/d/d-id/1028656?
- https://auth0.com/intro-to-iam/saml-vs-openid-connect-oidc/
- https://tools.ietf.org/html/rfc7519
脚注
Sessions, 也被称为服务器端Cookie (Server side cookies)。Sessions被保存在服务器上,客户端,也即浏览器仅Session ID。Session ID是Session的唯一标识 ,服务器用Session ID把客户端的请求与存储在服务器上的Sessions进行匹配。Sessions一般与用户的身份验证有关,有时也会包含用户偏好设置有关的信息,比如用户的语言偏好。于服务器端Cookie相对的是客户端Cookie,客户端Cookie也成为HTTP Cookie。服务端Cookie于客户端Cookie’的对比请参看 https://stackoverflow.com/questions/6922145/what-is-the-difference-between-server-side-cookie-and-client-side-cookie ↩︎
水平拓展,通过增加廉价服务器的方式增加Web服务器能够承担的负载,使其能够服务更多的用户,比如在1个Web服务器不能满足用户需求时,用2个Web服务器一起满足用户的需求。与之相对的是垂直拓展 (Vertical Scaling),通过增加已有服务器的配置来Web服务器能够承担的负载,比如在1个Web服务器不能满足用户需求时,用一个配置更高的Web服务器,比如CPU更快,内存更大的Web服务器替代原来的服务器。 ↩︎
负载均衡服务器,简称负载均衡器。是一种特殊的服务器,主要功能是负载分配给服务器。负载均衡器的类型很多,有的工作在OSI网络模型的传输层,具有很高的吞吐量。有的工作在应用层,可以根据HTTP的请求更智能的分配请求,比如把某个用户的请求总是分配给一个特定的服务器。 ↩︎
单点故障,是指系统中一旦失效,就会让整个系统无法运作的部件。https://en.wikipedia.org/wiki/Single_point_of_failure ↩︎
可用性:Availability。简单的说,可用性就是一个系统处在可工作状态的时间的比例。例如,服务A在一年时间里(8760小时)有8751小时可用。其可用性则为8751/8760 = 0.999,或以百分比表示99.9%。详情参见 https://en.wikipedia.org/wiki/Availability ↩︎
SSO,Single sign-on的缩写。又译为单一签入,一种对于许多相互关连,但是又是各自独立的软件系统,提供访问控制的属性。当拥有这项属性时,当用户登录时,就可以获取所有系统的访问权限,不用对每个单一系统都逐一登录。SSO的需求最先出现在对企业内网中不同服务的访问,这种功能通常是以轻型目录访问协议(LDAP)来实现,在服务器上会将用户信息存储到LDAP数据库中。后来这种需求广拓展到了对互联网上不同服务的访问,主要目的是让用户只需一个账号即可访问所有互相信任的应用系统。详情参见 https://en.wikipedia.org/wiki/Single_sign-on ↩︎
SAML,Security Assertion Markup Language的缩写。是一个基于XML的开源标准数据格式,它在当事方之间交换**身份验证 (Authentication)和授权 (Auhorization)**数据,尤其是在身份提供者 (IdP) 和服务提供者 (SP)之间交换。SAML是OASIS安全服务技术委员会的一个产品,始于2001年。详情参见 https://en.wikipedia.org/wiki/Security_Assertion_Markup_Language ↩︎
SOAP(原为Simple Object Access Protocol的首字母缩写,即简单对象访问协议)是交换数据的一种协议规范,使用在计算机网络Web服务(web service)中,交换带结构的信息。SOAP为了简化网页服务器(Web Server)从XML数据库中提取数据时,节省去格式化页面时间,以及不同应用程序之间按照HTTP通信协议,遵从XML格式执行资料互换,使其抽象于语言实现、平台和硬件。详情参见 https://zh.wikipedia.org/wiki/简单对象访问协议 ↩︎
表现层状态转换(英语:Representational State Transfer,缩写:REST)是Roy Thomas Fielding博士于2000年在他的博士论文[1]中提出来的一种万维网软件架构风格,目的是便于不同软件/程序在网络(例如互联网)中互相传递信息。表现层状态转换是根基于超文本传输协议(HTTP)之上而确定的一组约束和属性,是一种设计提供万维网络服务的软件构建风格。详情参见 https://zh.wikipedia.org/wiki/表现层状态转换 ↩︎
这句话翻译自"If you use Android, AWS, Microsoft Azure, Salesforce, or Google then chances are that you are already using JWT.",来源是 https://auth0.com/blog/jwt-json-webtoken-logo/ ↩︎
这一段话的来源参见 Application and Use Cases of OIDC and SAML https://auth0.com/intro-to-iam/saml-vs-openid-connect-oidc/ ↩︎








")



